
 3월 2, 2026
3월 2, 2026 
1. AI 에이전트 11명에게 스프린트를 통째로 맡겨봤습니다
AI-SDLC / Agentic Coding 주제로 또 하나의 실험을 했습니다. 혼자 순차적으로 할 일을 병렬로 쪼개서, 각각의 AI에게 동시에 시켰습니다. 결과는 흥미로웠습니다. 되긴 됩니다. 근데 조건이 있습니다.
2. 70분, 에이전트 11명, 아이템 9개
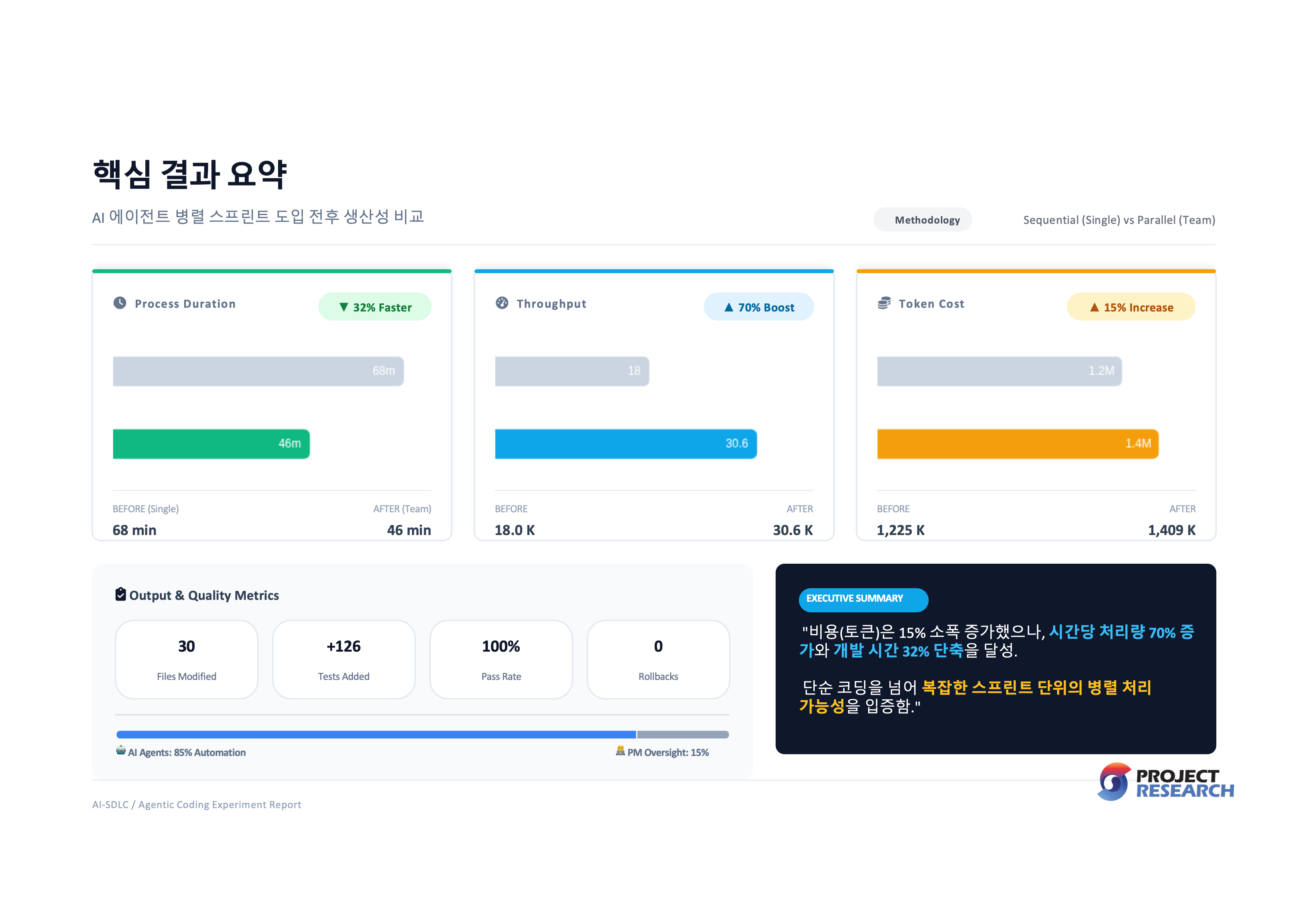
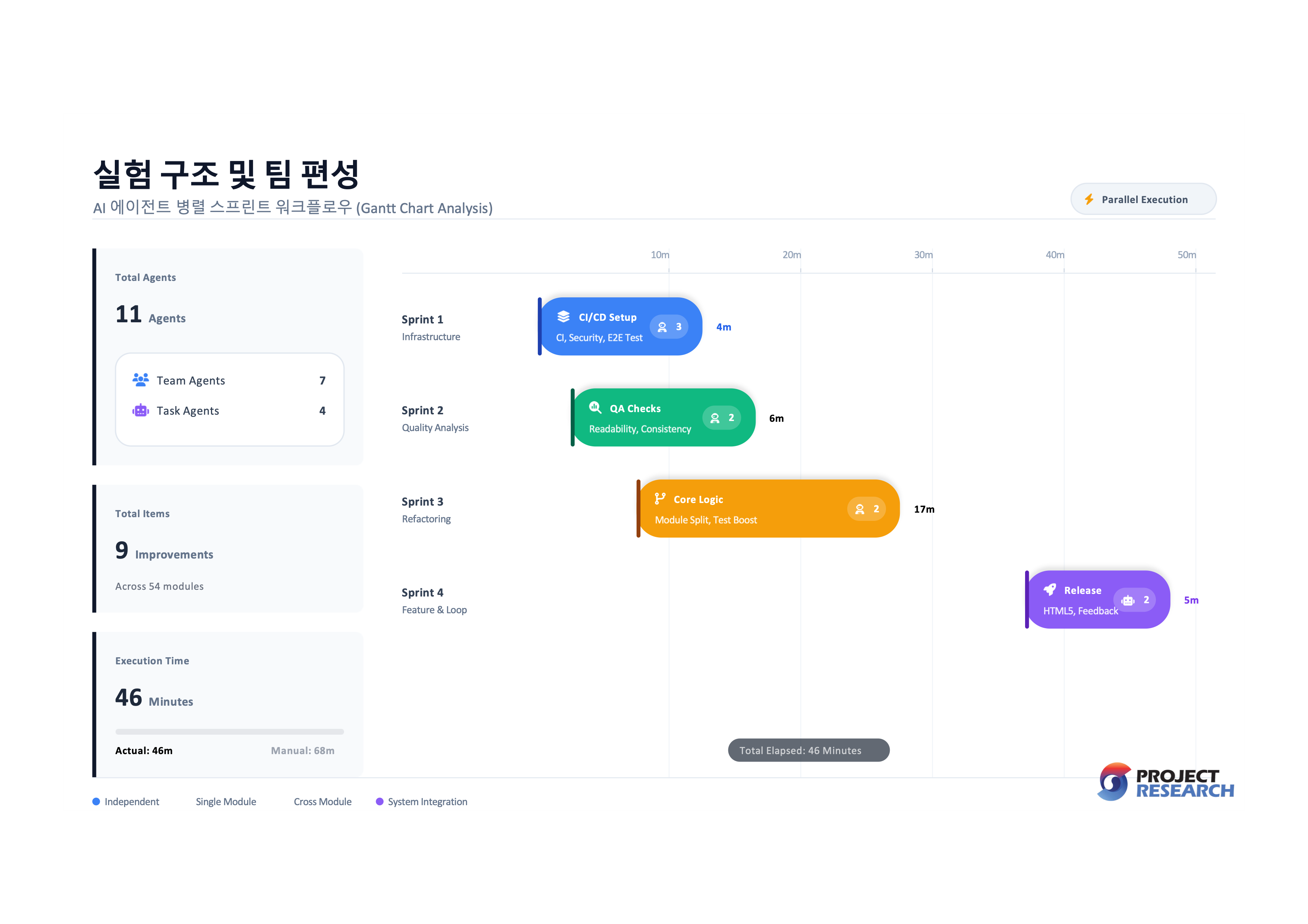
프로젝트 파이프라인(모듈 54개, 테스트 1,426개)에 9가지 개선을 한꺼번에 적용하고 싶었습니다. CI 커버리지, 보안 스캐닝, 야간 E2E 테스트, 영문 가독성 지표, 챕터 간 일관성 검증, 대형 모듈 분할, 멀티에이전트 테스트 보강, HTML5 출력, 에디터 피드백 루프.
4개 스프린트로 나눠 병렬 실행했습니다. 혼자 하면 68분, 팀 모드로 돌리니 46분. 토큰은 15% 더 썼지만(1,225K→1,409K) 시간은 32% 줄었습니다. 시간당 처리량은 18K→30.6K tokens/분, 70% 증가. 산출물은 30개 파일, +4,339/-1,704 LOC, 테스트 126개 추가. 나는 코드를 한 줄도 치지 않았습니다.
3. 에이전트는 반드시 성공하는 것은 아니다
11명 중 3명이 문제를 일으켰습니다. 한 명은 2,768줄짜리 모듈을 분할하다 순환 참조를 만들었습니다. 의존성 그래프를 분석하지 못한 거죠. 리더가 5분간 직접 수정해야 했습니다. 다른 한 명은 한국어 IME 버그로 tmux 명령에 “한글” 프리픽스가 붙어 실행 자체가 깨졌고, 또 한 명은 중간에 멈춰서 Task 에이전트로 전환해 재실행했습니다. (이는 claude 공식 bug report 했습니다.)
흥미로운 패턴이 보였습니다. 신규 파일 생성(CI 설정, 테스트)은 품질이 높았고, 크로스-모듈 리팩토링은 품질이 낮았습니다. 에이전트는 “함수를 옮겨라”는 잘하지만, “옮기면 뭐가 깨지는가”는 모릅니다. 최종 결과는 1,552 테스트 전체 통과, 롤백 0건. 하지만 멀티 에이전트는 100% 자동화가 아닙니다. 85% 자동화 + 15% 감독. 시스템 사고는 여전히 사람 몫입니다.
4. PM의 가치가 바뀐다
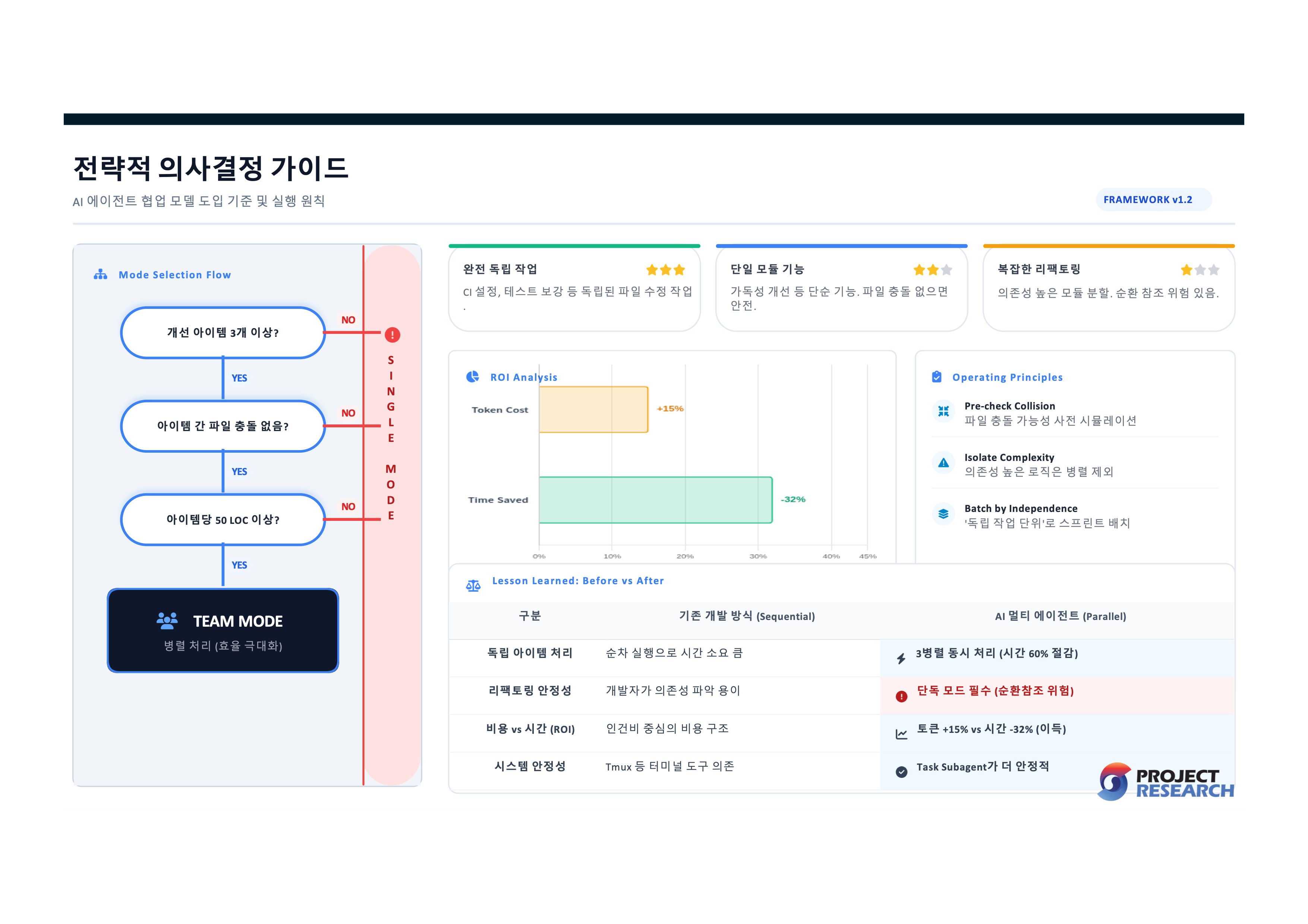
이번 실험에서 가장 크게 느낀 건, 팀 모드에서 PM의 역할이 완전히 달라진다는 점이었습니다. “이 두 아이템이 같은 파일을 건드리는가?” — 이 질문 하나가 병렬화의 성패를 갈랐습니다. CI 설정 3종(독립 파일)은 에이전트 3명이 완벽하게 동시 처리했지만, 모듈 리팩토링(의존성 높음)은 에이전트가 만든 버그를 내가 직접 고쳐야 했습니다.
판단 기준은 단순합니다. 독립 아이템 3개 이상이면 팀 모드, 파일이 겹치면 단독 모드. 아이템당 50 LOC 미만이면 오케스트레이션 오버헤드가 이득을 잡아먹으니 단독 모드. 하나 더, tmux team 방식보다 Task subagent 방식이 오류가 적었습니다. Sprint 4가 Sprint 1-3보다 안정적이었습니다.
5. 교훈
Agentic Coding에서 멀티 에이전트의 본질은 속도가 아닙니다. 태스크 분해 능력입니다. 즉 Architect/Domain/Spec 전문가가 일을 잘 쪼개면 32% 빨라지고, 잘못 쪼개면 순환 참조를 디버깅하는 데 시간을 씁니다. 코드를 잘 치는 것보다, 코드를 잘 나누는 것. 그게 AI 시대 PM의 핵심 역량이라는 걸, 이번 실험이 숫자로 증명했습니다.
#AgenticCoding #ClaudeCode #멀티에이전트 #AISDLC #TeamMode #AIPM




아직 댓글이 없습니다... 첫 번째로 댓글을 작성하세요!